percolator 和 watcher
在运维体系中,监控和报警总是成双成对的出现。ELKstack 在时序统计方面的便捷,在很多时候被作为监控的一种方式在使用。那么,自然就引申出一个问题:ELKstack 如何做报警?
对于简单而且固定需求的模式,我们可以在 Logstash 中利用 filter/metric 和 filter/ruby 等插件做预处理,直接 output/nagios 或 output/nagios 来报警;但是对于针对全局的、更复杂的情况,Logstash 就无能为力了。
目前比较通行的办法。有两种:
- 对于匹配报警,采用 ES 的 Percolator 接口做响应报警;
- 对于时序统计,采用定时任务方式,发送 ES aggs 请求,分析响应体报警。
针对报警的需求,ES 官方也在最近开发了 Watcher 商业产品,和 Shield 一样以 ES 插件形式存在。本节即稍微描述一下 Percolator 接口的用法和 Watcher 产品的思路。相信稍有编程能力的读者都可以根据自己的需求写出来类似的程序。
Percolator 接口
Percolator 接口和我们习惯的搜索接口正好相反,它要求预先定义好 query,然后通过接口提交文档看能匹配上哪个 query。也就是说,这是一个实时的模式过滤接口。
比如我们通过 syslog 来发现硬件报错的时候,可以预先定义 query:
# curl -XPUT http://127.0.0.1:9200/syslog/.percolator/memory -d '{
"query" : {
"query_string" : {
"default_field" : "message",
"default_operator" : "OR",
"query" : "mem DMA segfault page allocation AND severity:>2 AND program:kernel"
}
}
}'
# curl -XPUT http://127.0.0.1:9200/syslog/.percolator/disk -d '{
"query" : {
"query_string" : {
"default_field" : "message",
"default_operator" : "OR",
"query" : "scsi sata hdd sda AND severity:>2 AND program:kernel"
}
}
}'
然后,将标准的数据写入请求稍微做一点改动:
# curl -XPOST http://127.0.0.1:9200/syslog/msg/_percolate -d '{
"doc" : {
"timestamp" : "Jul 17 03:57:23",
"host" : "localhost",
"program" : "kernel",
"facility" : 0,
"severity" : 3,
"message" : "swapper/0: page allocation failure: order:4, mode:0x4020"
}
}'
得到如下结果:
{
...,
"total": 1,
"matches": [
{
"_index": "syslog",
"_id": "memory"
}
]
}
从结果可以看出来,这条 syslog 日志匹配上了 memory 异常。接下来就可以发送给报警系统了。
如果是 syslog 索引中已经有的数据,也可以重新过一遍 Percolator 接口:
# curl -XPOST http://127.0.0.1:9200/syslog/msg/existsid/_percoloate
利用更复杂的 query DSL 做 Percolator 请求的示例,推荐阅读官网这篇 geo 定位的文章:https://www.elastic.co/blog/using-percolator-geo-tagging
Watcher 产品
Watcher 也是 Elastic.co 公司的商业产品,和 Shield,Marvel 一样插件式安装即可:
bin/plugin -i elasticsearch/license/latest
bin/plugin -i elasticsearch/watcher/latest
Watcher 使用方面,也提供标准的 RESTful 接口,示例如下:
# curl -XPUT http://127.0.0.1:9200/_watcher/watch/error_status -d'
{
"trigger": {
"schedule" : { "interval" : "5m" }
},
"input" : {
"search" : {
"request" : {
"indices" : [ "<logstash-{now/d}>", "<logstash-{now/d-1d}>" ],
"body" : {
"query" : {
"filtered" : {
"query" : { "match" : { "status" : "error" }},
"filter" : { "range" : { "@timestamp" : { "from" : "now-5m" }}}
}
}
}
}
}
},
"condition" : {
"compare" : { "ctx.payload.hits.total" : { "gt" : 0 }}
},
"transform" : {
"search" : {
"request" : {
"indices" : [ "<logstash-{now/d}>", "<logstash-{now/d-1d}>" ],
"body" : {
"query" : {
"filtered" : {
"query" : { "match" : { "status" : "error" }},
"filter" : { "range" : { "@timestamp" : { "from" : "now-5m" }}}
}
},
"aggs" : {
"topn" : {
"terms" : {
"field" : "userid"
}
}
}
}
}
}
},
"actions" : {
"email_admin" : {
"throttle_period" : "15m",
"email" : {
"to" : "admin@domain",
"subject" : "Found {{ctx.payload.hits.total}} Error Events",
"priority" : "high",
"body" : "Top10 users:\n{{#ctx.payload.aggregations.topn.buckets}}\t{{key}} {{doc_count}}\n{{/ctx.payload.aggregations.topn.buckets}}"
}
}
}
}'
上面这行命令,意即:
- 每 5 分钟,向最近两天的
logstash-yyyy.MM.dd索引发起一次条件为最近五分钟,status 字段内容为 error 的查询请求; - 对查询结果做 hits 总数大于 0 的判断;
- 如果为真,再请求一次上述条件下,userid 字段的 Top 10 数据集作为后续处理的来源;
- 如果最近 15 分钟内未发送过报警,则向
admin@domain邮箱发送一个标题为 "Found N erroneous events",内容为 "Top10 users" 列表的报警邮件。
整个请求体顺序执行。目前 trigger 只支持 scheduler 方式,input 支持 search 和 http 方式,actions 支持 email,logging,webhook 方式,transform 是可选项,而且可以设置在 actions 里,不同 actions 做不同的 payload 转换。
condition, transform 和 actions 中,默认使用 Watcher 增强版的 xmustache 模板语言,也可以使用固化的脚本文件,比如有 threshold_hits.groovy 的话,可以执行:
"condition" : {
"script" : {
"file" : "threshold_hits",
"params" : {
"threshold" : 0
}
}
}
完整的 Watcher 插件内部执行流程如下图。相信有编程能力的读者都可以用 crontab/at 配合 curl,email 工具仿造出来类似功能的 shell 脚本。
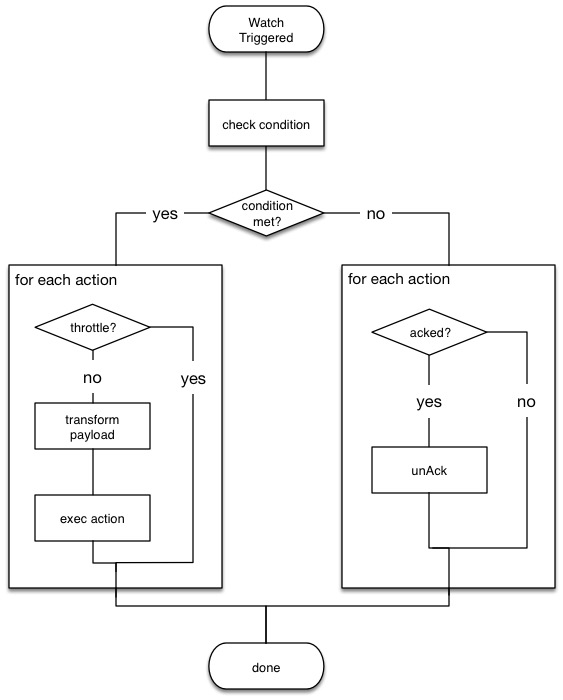
注意:
在 search 中,对 indices 内容可以写完整的索引名比如 syslog,也可以写通配符比如 logstash-*,也可以写时序索引动态定义方式如 <logstash-{now/d}>。而这个动态定义,Watcher 是支持根据时区来确定的,这个需要在 elasticsearch.yml 里配置一行:
watcher.input.search.dynamic_indices.time_zone: '+08:00'